In this post, we connect the Siegel upper half-space to denoising diffusion probabilistic models (DDPMs), and explore a way of navigating the Siegel upper half-space.
Denoising diffusion probabilistic models
Denoising diffusion probabilistic models (DDPMs) generate data by iteratively removing small amounts of Gaussian noise. This is typically done over hundreds of time steps. This generation process is the time-reversal of the learning process. The idea is to start with a given datapoint 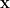
In other words, with DDPMs, we attempt to learn a generative model 









The Siegel upper half-space and multivariate normal distributions
The diffusion process as described above can be viewed as a path through (a subspace of) the parameter space of multivariate normal distributions. In other words, it is a trajectory through the moduli space of multivariate normal distributions. We can view this moduli space as the Siegel upper half-space 



The reasoning is as follows. Covariance matrices are symmetric. When there is no linear relationship between features (ie, uncorrelated features), a covariance matrix is positive-definite; when there is a linear relationship between features (ie, has correlated features), a covariance matrix is positive semi-definite. Then we can view the covariance matrix 






Diffusion models typically use isotropic covariance matrices. The reasons include computational efficiency and tractability, ease of optimization, and theoretical conventions. However, if we can capture more of the overall noise by using general (not isotropic) covariance matrices, and if we can navigate between these distributions intentionally, then we should be able to use fewer time steps in the diffusion process. This would allow us to considerably speed up diffusion modeling.
How can we learn trajectories through the Siegel upper half-space
Consider the Siegel-Jacobi space of complex dimension 



Now consider the natural group action on the Siegel-Jacobi 



where 


We now have a way to navigate the moduli space of normal distributions and, in principle, to run diffusion models, with deep connections to number theory, automorphic forms, conformal field theory, and many other areas of math and physics. The form of this action is also strikingly similar to that of structured state space models (S4) for very long sequence learning. Given the roots of diffusion models in thermodynamics, these are intriguing results.

Leave a comment